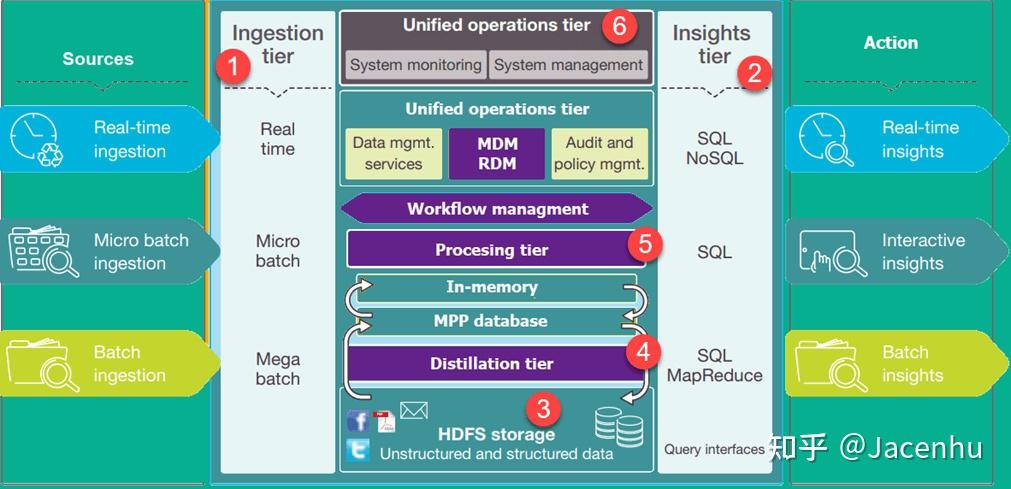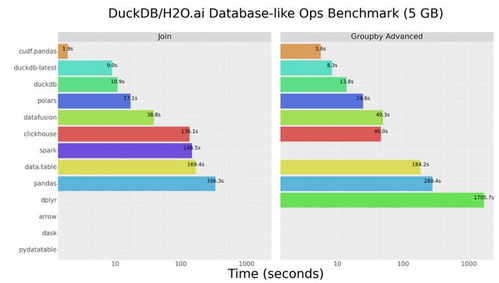
在Python數(shù)據(jù)科學(xué)領(lǐng)域,Pandas長期以來是數(shù)據(jù)處理與分析的事實(shí)標(biāo)準(zhǔn)。隨著數(shù)據(jù)規(guī)模的爆炸式增長,其性能瓶頸日益凸顯。如今,一個名為Polars的新星正迅速崛起,以其卓越的速度與內(nèi)存效率,成為處理大規(guī)模數(shù)據(jù)集的有力競爭者。
為什么需要Polars?
Pandas基于NumPy構(gòu)建,雖然功能強(qiáng)大,但在處理GB級甚至TB級數(shù)據(jù)時,常受限于單線程運(yùn)算和內(nèi)存消耗。Polars則專為現(xiàn)代硬件設(shè)計,采用Apache Arrow作為內(nèi)存模型,并利用Rust語言編寫核心引擎,實(shí)現(xiàn)了真正的多線程并行計算。
Polars的核心優(yōu)勢
- 閃電般的速度:在基準(zhǔn)測試中,Polars的某些操作比Pandas快10倍甚至100倍,尤其在分組聚合、連接操作和大數(shù)據(jù)過濾場景下表現(xiàn)突出。
- 極致的內(nèi)存效率:Arrow列式存儲大幅減少了內(nèi)存占用,且支持流式處理,允許處理遠(yuǎn)超內(nèi)存大小的數(shù)據(jù)集。
- 優(yōu)雅的API設(shè)計:提供類似Pandas的易用性,同時引入更一致的鏈?zhǔn)秸{(diào)用方法,代碼更簡潔、表達(dá)力更強(qiáng)。
- 無縫集成生態(tài):可與NumPy、Pandas互操作,并支持從CSV、Parquet、數(shù)據(jù)庫等多種數(shù)據(jù)源直接讀取。
入門示例:快速體驗(yàn)Polars
`python
import polars as pl
# 讀取數(shù)據(jù)
df = pl.readcsv('largedataset.csv')
# 鏈?zhǔn)讲僮鳎汉Y選、分組、聚合
result = (df.filter(pl.col('sales') > 1000)
.group_by('category')
.agg(pl.col('revenue').sum()))
# 轉(zhuǎn)換為Pandas DataFrame(如需)
pandasdf = result.topandas()`
何時選擇Polars?
- 處理數(shù)百萬行以上的數(shù)據(jù)集時
- 需要頻繁進(jìn)行復(fù)雜轉(zhuǎn)換與聚合時
- 追求極致性能,減少等待時間時
- 內(nèi)存有限,需處理超出內(nèi)存的數(shù)據(jù)時
平衡之道:Polars與Pandas共存
盡管Polars優(yōu)勢明顯,但Pandas憑借其成熟的生態(tài)系統(tǒng)和廣泛的社區(qū)支持,在中小型數(shù)據(jù)、快速原型開發(fā)及教育領(lǐng)域仍不可替代。明智的做法是根據(jù)場景靈活選擇:
- Polars:生產(chǎn)環(huán)境中的大規(guī)模數(shù)據(jù)處理、性能關(guān)鍵型任務(wù)。
- Pandas:數(shù)據(jù)探索、小規(guī)模分析、與大量現(xiàn)有Pandas代碼庫集成。
未來展望
Polars正快速發(fā)展,社區(qū)日益活躍。其路線圖包括更豐富的SQL支持、機(jī)器學(xué)習(xí)集成及更完善的IO功能。對于數(shù)據(jù)工程師和科學(xué)家而言,掌握Polars正成為一種有價值的技能,它不僅是Pandas的補(bǔ)充,更是面向未來大數(shù)據(jù)挑戰(zhàn)的下一代解決方案。
結(jié)論:Pandas不會消失,但Polars的出現(xiàn)標(biāo)志著Python數(shù)據(jù)處理進(jìn)入了‘多核并行、內(nèi)存高效’的新時代。在數(shù)據(jù)規(guī)模不斷膨脹的今天,將這個‘神器’加入工具箱,無疑能讓你的數(shù)據(jù)處理工作如虎添翼。